Pyhon Lru Cache with time expiration

Caching and Its Uses
Caching is an optimization technique that you can use in your applications to keep recent or often-used data in memory locations that are faster or computationally cheaper to access than their source.
Imagine you're building a newsreader application that fetches the latest news from different sources. As the user navigates through the list, your application downloads the articles and displays them on the screen.
What would happen if the user decided to move repeatedly back and forth between a couple of news articles? Unless you were caching the data, your application would have to fetch the same content every time! That would make your user's system sluggish and put extra pressure on the server hosting the articles.
A better approach would be to store the content locally after fetching each article. Then, the next time the user decided to open an article, your application could open the content from a locally stored copy instead of going back to the source. In computer science, this technique is called caching.
Caching Strategies
There's one big problem with this cache implementation: the content of the dictionary will grow indefinitely! As the user downloads more articles, the application will keep storing them in memory, eventually causing the application to crash.
To work around this issue, you need a strategy to decide which articles should stay in memory and which should be removed. These caching strategies are algorithms that focus on managing the cached information and choosing which items to discard to make room for new ones.
There are several different strategies that you can use to evict items from the cache and keep it from growing past from its maximum size. Here are five of the most popular ones, with an explanation of when each is most useful:
| Strategy | Eviction policy | Use case |
|---|---|---|
| First-In/First-Out (FIFO) | Evicts the oldest of the entries | Newer entries are most likely to be reused |
| Last-In/First-Out (LIFO) | Evicts the latest of the entries | Older entries are most likely to be reused |
| Least Recently Used (LRU) | Evicts the least recently used entry | Recently used entries are most likely to be reused |
| Most Recently Used (MRU) | Evicts the most recently used entry | Least recently used entries are most likely to be reused |
| Least Frequently Used (LFU) | Evicts the least often accessed entry | Entries with a lot of hits are more likely to be reused |
n the sections below, you'll take a closer look at the LRU strategy and how to implement it using the @lru_cache decorator from Python's functools module.
LRU (least recently used) Cache
The least recently used (LRU) cache works on the idea that pages that have been most heavily used in the past few instructions are most likely to be used heavily in the next few instructions too. While LRU can provide near-optimal performance in theory (almost as good as adaptive replacement cache), it is rather expensive to implement in practice.
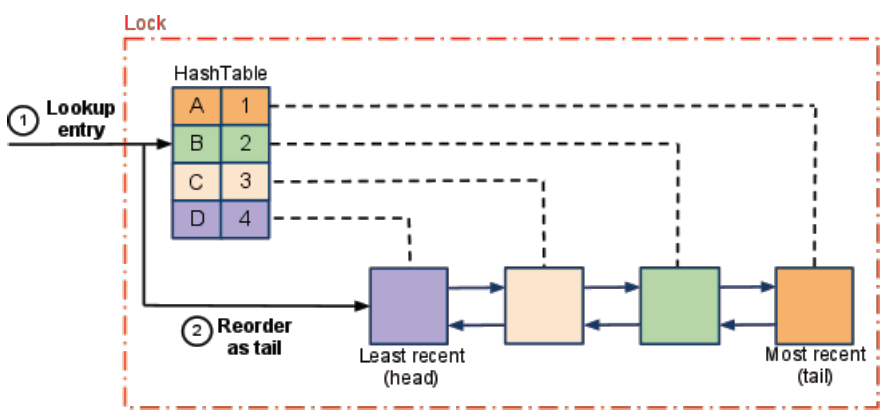
A cache implemented using the LRU strategy organizes its items in order of use. Every time you access an entry, the LRU algorithm will move it to the top of the cache. This way, the algorithm can quickly identify the entry that's gone unused the longest by looking at the bottom of the list.
Python Lru Cache
@functools.lru_cache(maxsize=128, typed=False)
Decorator to wrap a function with a memoizing callable that saves up to the maxsize most recent calls. It can save time when an expensive or I/O bound function is periodically called with the same arguments.
Since a dictionary is used to cache results, the positional and keyword arguments to the function must be hashable.
Distinct argument patterns may be considered to be distinct calls with separate cache entries. For example, f(a=1, b=2) and f(b=2, a=1) differ in their keyword argument order and may have two separate cache entries.
If user_function is specified, it must be a callable. This allows the lru_cache decorator to be applied directly to a user function, leaving the maxsize at its default value of 128:
@lru_cache
def count_vowels(sentence):
return sum(sentence.count(vowel) for vowel in 'AEIOUaeiou')
If maxsize is set to None, the LRU feature is disabled and the cache can grow without bound.
If typed is set to true, function arguments of different types will be cached separately. If typed is false, the implementation will usually regard them as equivalent calls and only cache a single result. (Some types such as str and int may be cached separately even when typed is false.)
The wrapped function is instrumented with a cache_parameters() function that returns a new dict showing the values for maxsize and typed. This is for information purposes only. Mutating the values has no effect.
To help measure the effectiveness of the cache and tune the maxsize parameter, the wrapped function is instrumented with a cache_info() function that returns a named tuple showing hits, misses, maxsize and currsize.
The decorator also provides a cache_clear() function for clearing or invalidating the cache.
Python @lru_cache example
First, I'll define a Python function that calculates the n-th Fibonacci number :
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
return fibonacci(n - 1) + fibonacci(n - 2)
This fibonacci function will serve as an example of an "expensive" computation. Calculating the n-th Fibonacci number this way has O(2^n) time complexity
— it takes exponential time to complete. This makes it quite an expensive function indeed.
Next up, I'm going to do some benchmarking in order to get a feel for how computationally expensive this function is. Python's built-in timeit module lets me measure the execution time in seconds of an arbitrary Python statement.
import timeit
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
return fibonacci(n - 1) + fibonacci(n - 2)
print(timeit.timeit('fibonacci(40)', globals=globals(), number=1))
# output:
# 42.08397298492491
As you can see, on my machine, it takes about 42 seconds to compute the 40th number in the Fibonacci sequence. That's a pretty slow and expensive operation right there.
LRU_Cache in code:
Now, I'll implement n-th Fibonacci number with @lru_cache decorator:
import functools
import timeit
@functools.lru_cache(maxsize=128)
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
return fibonacci(n - 1) + fibonacci(n - 2)
print(timeit.timeit('fibonacci(40)', globals=globals(), number=1))
print(fibonacci.cache_info())
# output:
# 4.309415817260742e-05
# CacheInfo(hits=38, misses=41, maxsize=128, currsize=41)
Now, fibonnaci function is more quickly - about 4.3e-05 seconds.
Adding Cache Expiration
Imagine you want to develop a script that monitors some url and prints number of word 'email' in such article.
|
|
- line 7 - define a url with article as variable
- line 8 - define a monitored word as variable
- line 11 -
get_article_from_server(url)- function for download first 1200 bytes from article and return count of monitored word - line 19 - monitor() will loop indefinitely
- line 25 - the code sleeps for 5 seconds before continuing
Every time the script loads an article, the message "Fetching article from server over Internet..." is printed to the console. If you let the script run long enough, then you'll see how this message shows up repeatedly, even when loading the same link.
output:
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Fetching article from server over Internet...
2
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Fetching article from server over Internet...
2
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Fetching article from server over Internet...
2
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Fetching article from server over Internet...
2
This is an excellent opportunity to cache the article's contents and avoid hitting the network every five seconds. You could use the @lru_cache decorator, but what happens if the article's content is updated?
The first time you access the article, the decorator will store its content and return the same data every time after. If the post is updated, then the monitor script will never realize it because it will be pulling the old copy stored in the cache. To solve this problem, you can set your cache entries to expire.
Python @lru_cache with Time and Space expire
The @lru_cache decorator evicts existing entries only when there's no more space to store new listings. With sufficient space, entries in the cache will live forever and never get refreshed.
This presents a problem for your monitoring script because you'll never fetch updates published for previously cached articles. To get around this problem, you can update the cache implementation so it expires after a specific time.
You can implement this idea into a new decorator that extends @lru_cache. If the caller tries to access an item that's past its lifetime, then the cache won't return its content, forcing the caller to fetch the article from the network.
Here's a possible implementation of this new decorator:
|
|
- line 4 - The
@timed_lru_cachedecorator will support the lifetime of the entries in the cache (in seconds) and the maximum size of the cache. - line 8 - the code wraps the decorated function with the lru_cache decorator. This allows you to use the cache functionality already provided by lru_cache.
- line 10 and 12 - These two lines instrument the decorated function with two attributes representing the lifetime of the cache and the actual date when it will expire.
- line 18 to 21 - Before accessing an entry in the cache, the decorator checks whether the current date is past the expiration date. If that's the case, then it clears the cache and recomputes the lifetime and expiration date.
Notice how, when an entry is expired, this decorator clears the entire cache associated with the function. The lifetime applies to the cache as a whole, not to individual articles. A more sophisticated implementation of this strategy would evict entries based on their individual lifetimes.
Python script with @lru_cache time expiration
You can now use your new @timed_lru_cache decorator with the cache.py script to prevent fetching the content of an article every time you access it. Putting the code together in a single script for simplicity, you end up with the following:
import urllib.request
import time
from functools import lru_cache, wraps
from datetime import datetime, timedelta
url = 'https://www.mybluelinux.com/what-is-email-envelope-and-email-header/'
word = 'email'
def timed_lru_cache(seconds: int, maxsize: int = None):
def wrapper_cache(func):
print('I will use lru_cache')
func = lru_cache(maxsize=maxsize)(func)
print('I\'m setting func.lifetime')
func.lifetime = timedelta(seconds=seconds)
print('I\'m setting func.expiration')
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
print('Check func expiration')
print(f'datetime.utcnow(): {datetime.utcnow()}, func.expiration: {func.expiration}')
if datetime.utcnow() >= func.expiration:
print('func.expiration lru_cache lifetime expired')
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(20)
def get_article_from_server(url):
print("Fetching article from server over Internet...")
with urllib.request.urlopen(url) as req:
text = req.read(1200).decode('utf-8')
return text.count(word)
def monitor(url):
while True:
print(f'\nChecking url {url}')
count = get_article_from_server(url)
print(count)
time.sleep(5)
if __name__ == "__main__":
monitor(url=url)
Run the script and take a look at the results:
I will use lru_cache
I'm setting func.lifetime
I'm setting func.expiration
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Check func expiration
datetime.utcnow(): 2022-03-15 22:42:24.885475, func.expiration: 2022-03-15 22:42:44.885430
Fetching article from server over Internet...
16
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Check func expiration
datetime.utcnow(): 2022-03-15 22:42:29.922300, func.expiration: 2022-03-15 22:42:44.885430
16
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Check func expiration
datetime.utcnow(): 2022-03-15 22:42:34.926274, func.expiration: 2022-03-15 22:42:44.885430
16
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Check func expiration
datetime.utcnow(): 2022-03-15 22:42:39.930265, func.expiration: 2022-03-15 22:42:44.885430
16
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Check func expiration
datetime.utcnow(): 2022-03-15 22:42:44.935416, func.expiration: 2022-03-15 22:42:44.885430
func.expiration lru_cache lifetime expired
Fetching article from server over Internet...
16
Checking url https://www.mybluelinux.com/what-is-email-envelope-and-email-header/
Check func expiration
datetime.utcnow(): 2022-03-15 22:42:49.953502, func.expiration: 2022-03-15 22:43:04.935456
16
.
.
.
Notice how the code prints the message "Fetching article from server over Internet..." the first time it accesses the matching articles. After that, depending on your network speed and computing power, the script will retrieve the articles from the cache either one or two times before hitting the server again.
The script tries to access the articles every 5 seconds, and the cache expires every 20 seconds. These times are probably too short for a real application, so you can get a significant improvement by adjusting these configurations.
















