Fallacies of Distributed Systems
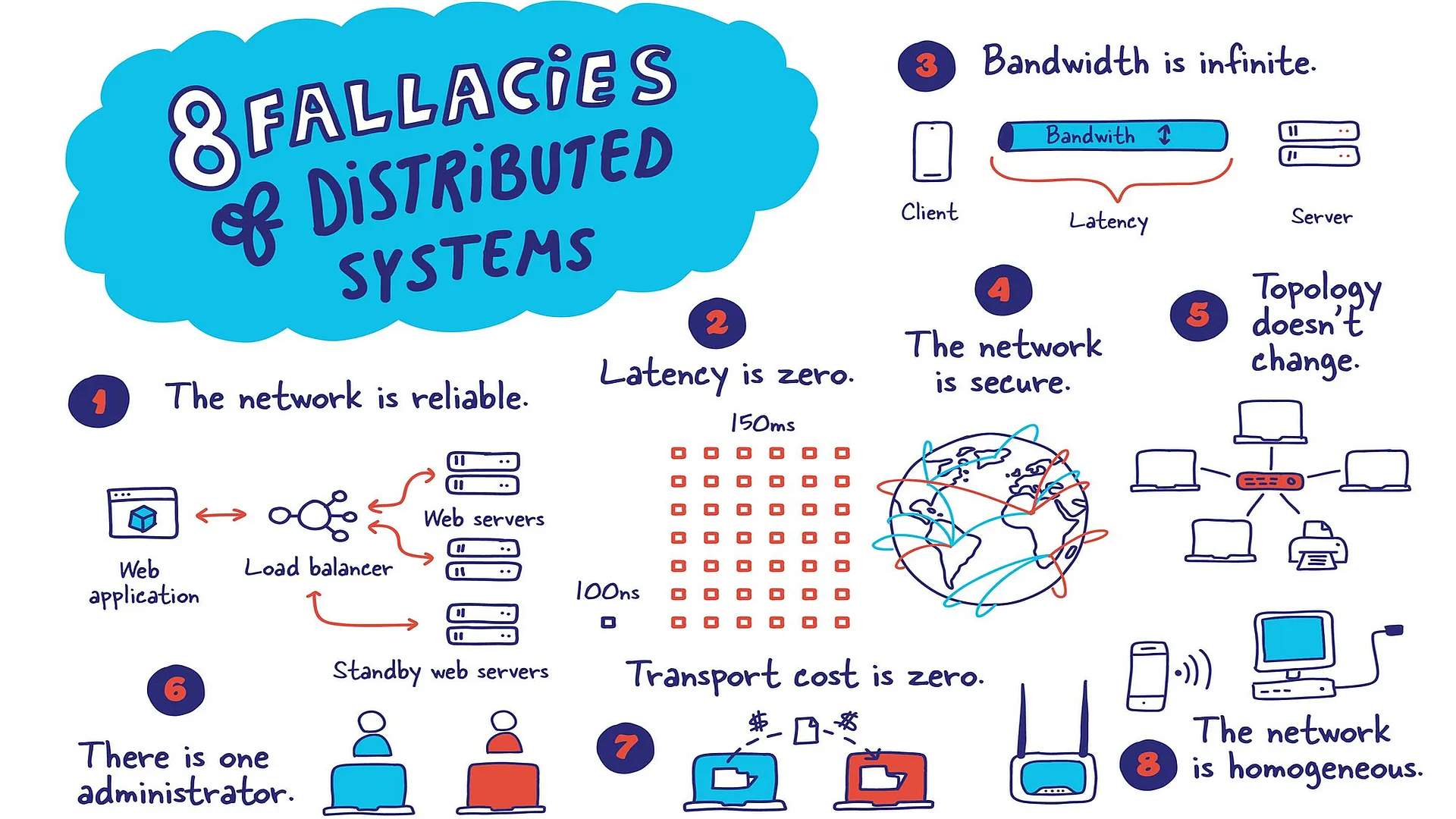
Fallacies of distributed systems are a set of assertions made by L Peter Deutsch and others at Sun Microsystems describing false assumptions that programmers new to distributed applications invariably make.
The mass adoption of microservices has forced more engineers to understand the implications of that decision within their systems.
I often see these 8 fallacies generally ignored or downplayed when discussing system design.
 Fallacies of Distributed Systems Infographic
Fallacies of Distributed Systems Infographic
I thought it might be fun to cover them and their potential mitigations.
What is a microservice?
Microservices - also known as the microservice architecture - is an architectural style that structures an application as a collection of services that are
- Highly maintainable and testable
- Loosely coupled
- Independently deployable
- Organized around business capabilities
- Owned by a small team
The microservice architecture enables the rapid, frequent and reliable delivery of large, complex applications. It also enables an organization to evolve its technology stack.
The network is reliable
 The network is reliable
The network is reliable
To build a reliable system, you have to understand and come to terms with the fact that any particular communication can fail; Therefore, we need to provide a way for systems to deal with this potential miscommunication. So ultimately, this comes down to retransmission, which can come in many forms.
One such pattern is the store and forward pattern. Instead of sending the data directly to the downstream server, we store it locally or elsewhere. This also allows for recovery in catastrophic scenarios where a simple retry loop would have lacked such guarantees.
There are multitudes of technologies that fit his pattern RabbitMQ , ActiveMQ and various proprietary solution from your favourite cloud vendor.
Latency is zero
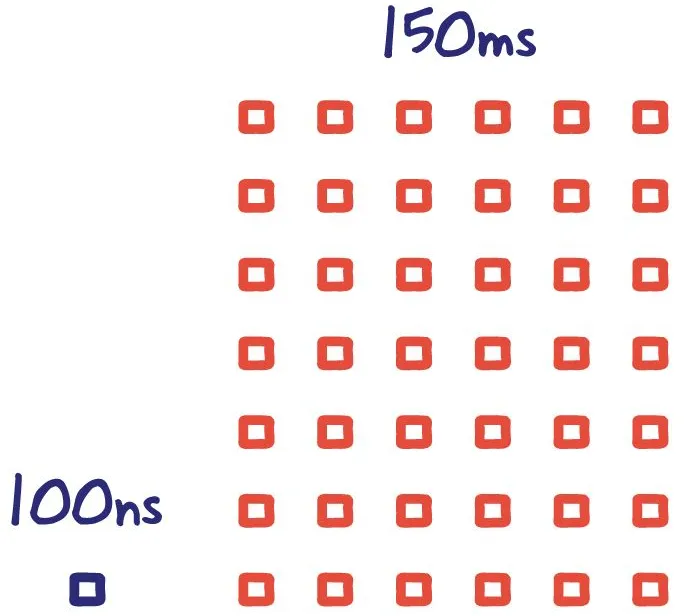 Pictured on the left is the time to access memory in a modern system, on the right the time it takes to do a round trip across the world.
Pictured on the left is the time to access memory in a modern system, on the right the time it takes to do a round trip across the world.
I like to think about latency as strictly overhead to get any request done. Message can be large, or it can be small, and latency is unchanged. Unlike bandwidth, latency usually has to do with the speed of light and the communication distance (or path). So the distance between the two systems plays a significant role here.
Latency is omnipresent. It occurs in all communication.
Ideally, this overhead should be small as possible. Latency is very similar to unloading groceries from the car. The time it takes you to travel from the kitchen to the car is latency.
Do you want to grab as much as you can in one trip, or do you want to bring the items individually, taking several hundred round-trips to unload the car?
What is a CDN?
A content delivery network (CDN) refers to a geographically distributed group of servers which work together to provide fast delivery of Internet content.
A CDN allows for the quick transfer of assets needed for loading Internet content including HTML pages, javascript files, stylesheets, images, and videos. The popularity of CDN services continues to grow, and today the majority of web traffic is served through CDNs, including traffic from major sites like Facebook, Netflix, and Amazon.
Content delivery networks and edge computing are essentially trying to make the distance between the fridge and trunk as close as possible. By duplicating the data closer to where it is needed we significantly reduce latency.
Bandwidth is infinite
 Bandwidth is infinite
Bandwidth is infinite
Assuming that you continue to increase data size on a channel without limit; can be quite the mistake. This problem only turns its head when scale difficulties enter the conversation, and specific communication channels hit their limits.
I first ran into this problem when I accidentally increased the payload that my homepage needed to function by a factor of 10. This specific API was an uncached call for 3 MBs on every page load. This included a round trip to the database as well for the entire payload.
We quickly hit several bandwidth limits in our system, which brought the site down fairly quickly.
Now you may be thinking you just told me to take as much as I could on each round trip to reduce the effects of latency. That is true, but it does have its limits. This depend highly on your systems design and respective priorities but being aware of the trade off is critically important.
The network is secure
 The network is secure
The network is secure
Assuming you can trust the network you are on or the people you are building your system for can be a crucial mistake.
Nowadays, this has become even more apparent with the advent of crowdsourced bug bounty programs and significant exploits in the news every day.
Taking a security-first stance when designing your systems will reap dividends in the future. Even taking the time to assess your current system for security vulnerabilities can be a great place to start and will quickly produce a short list for improvement.
Topology doesn't change
 Topology doesn't change
Topology doesn't change
Network structure won't always be the same. For example, if a critical piece of infrastructure goes down, can the traffic continue to flow to appropriate destinations? Do we have single point of failure?
With the advent of Docker and Kubernetes, the ease of changing network topology now almost makes us take it for granted, almost dangerously so.
Tools like Zookeeper and Consul really help resolve problems around service discovery and allow applications to react to changes in the layout and make up of our systems.
Building systems that can react to these change in topology can be tricky, but ultimately result in much more resilient systems.
There is one administrator
 There is one administrator
There is one administrator
This one took me some time to grasp, essentially saying that you can't control everything.
As your systems grow, they will rely on other systems outside your control. So take a second to think about all the dependencies; you have everything from your code down to the servers you run them on.
It's essential to have a clear way of managing your systems and their respective configurations. As the number of systems with various configuration increases it becomes hard to manage and track. Infrastructure as Code (IaC) can help codify those variations in your systems.
Having a good way of diagnosing issues when they come up, monitoring and observability will be critical tools that can save you hours.
Appropriate decoupling can also help ensure overall system resiliency and uptime.
What is Infrastructure as Code (IaC)?
Infrastructure as Code (IaC) is the managing and provisioning of infrastructure through code instead of through manual processes.
With IaC, configuration files are created that contain your infrastructure specifications, which makes it easier to edit and distribute configurations. It also ensures that you provision the same environment every time. By codifying and documenting your configuration specifications, IaC aids configuration management and helps you to avoid undocumented, ad-hoc configuration changes.
Transport cost is zero
 Transport cost is zero
Transport cost is zero
We often think that the resources we use to send data between systems are a simple business cost. Now when things are small, this overhead and cost can be negligible.
Still, as systems grow, that cost may be worth optimizing message formats like JSON can be a bit heavy (pun intended) compared to transfer optimized formats like gRPC or MessagePack.
Being aware of such costs is essential; however, it does have its tradeoffs. Doing so early may create more headache than its worth in the near term.
The network is homogeneous
 The network is homogeneous
The network is homogeneous
I have written my fair share of shims in my day; taking one format of data and transforming it into another.
We like everything to be clean and tidy, but the real world is far from it. Being interoperable is essential.
This flexibility ensures our systems continue to function when the "new hot framework" comes into play or when you need to run your new system in environments it wasn't intended for. (obviously, interoperability has its limits)
Knowing that all systems aren't the same and not coupling your solution to one aspect can save you time and headaches down the road.
















