Database Sharding Explained
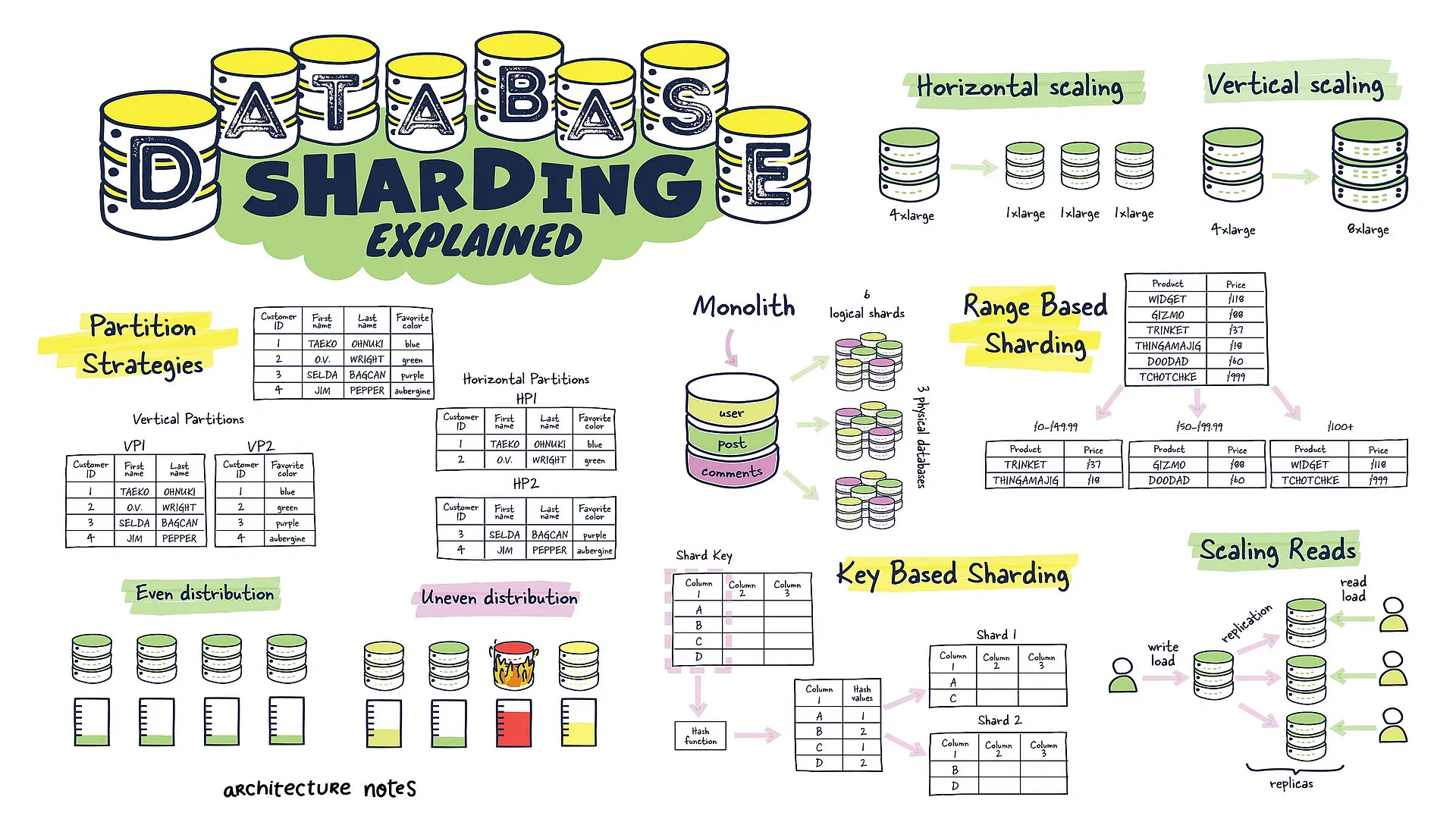
Your app is getting better. It has more features, more active users, and every day it collects more data. Your database is now causing the rest of your application to slow down. Database sharding might be the answer to your problems, but many people don't know what it is and, most importantly, when to use it. In this article, we'll talk about what database sharding is, how it works, and the best ways to use it.
Before we get into that question, it's essential to understand why we shard data stores and the various options you have before you embark on sharding.
Database Sharding Infographic
When tables get to a specific size, people often feel sharding is a magical solution to all scaling issues. However, I have had tables with billions of rows and didn't see a compelling reason to shard since my usage pattern lent itself well to a single table and didn't see any strong reasons (other than management of such a large table, which in some cases is reason enough) to shard the table.
What is it to shard a database
Simply put, sharding is a method for distributing data across multiple machines. Sharding becomes especially handy when no single machine can handle the expected workload.
Sharding is an example of horizontal scaling, while vertical scaling is an example of just getting larger and larger machines to support the new workload.
 Horizontal Scaling
Horizontal Scaling
Engineers often get caught up in doing things the most involved way, but keeping things simple early on makes challenging things later on as your application evolves much easier. So if your problem goes away by getting machines with more resources, 9/10, that's the correct answer.
Now that we have discussed the potential server architectures, let us talk about data layout.
You can also partition data in a few ways and move specific tables to their databases, much akin to what you see in microservice architectures, where a particular aspect of your application has its database server. The application is aware of where to look for each. Alternatively, you can store rows of the same table across multiple database nodes, which brings in ideas like sharding keys; more on that later.
 Database Partition Strategies
Database Partition Strategies
More modern databases like Cassandra and others abstract that away from the application logic and its maintained at the database level.
What are my options before sharding
Like any distributed architecture, database sharding costs money. Setting up shards, keeping the data on each shard up to date, and making sure requests are sent to the right shards is time-consuming and complicated. Before you start sharding, you might want to see if one of these other options will work for you.
Option 1: Do nothing
The number of times I have been asked if sharding is a good idea without any clear bottleneck or limiting factor like running out of hardware that can support the workload. If it isn't broken, don't fix it.
Option 2: Vertical Scaling
We have eluded to this before just get machines with more resources, adding additional RAM, adding more CPU cores for computationally heavy workloads, and adding additional storage. These are all options that don't require redesign of both your application and databases architectures. Other eventual limits, such as bandwidth (network or internal to the system), can also force you into sharding.
 Database Vertical Scaling
Database Vertical Scaling
Option 3: Replication
If most of what you do with your data is to read it, replication can make it more available and speed up how fast you can read it. This can help you avoid some of the complexity of database sharding. Read performance can be improved by making more copies of the database. Assuming you have already supplemented with caches of course. This can be done through load balancing or by routing queries based on where they are in the world. But replication makes write-heavy workloads harder to handle because each write must be copied to every node. This can vary depending on the datastore some of them do it asynchronously while others might delay the initial write to ensure its been replicated.
What is WAL
A WAL (write ahead log) is an extra structure on the disc that can only be added to. Before the changes are written to the database, they are first written to the log, this log must be on durable storage. It is used to recover from crashes and lost transactions. This log is also used to support replication in certain databases like PostgreSQL and MySQL. Scaling Reads
Scaling Reads
Options 4: Specialized Databases
Poor performance is caused by a database that needs to be better designed for the workload it serves. For example, storing search data in a relational datastore might make little sense. Moving something like that off to Elasticsearch is more effective. Moving blobs to an object store like S3 can be a considerable win rather than storing them in your relational store. It might make more sense to outsource this function than to try to shard your whole database.
A sharded database may be the best way to go if your application database manages a lot of data, needs a lot of reads and writes, and/or needs to be available at all times. Let's take a look at the pros and cons of sharding.
Sharding If You Must
Sharding can give you almost unlimited scalability in terms of increased system throughput, storage capacity, and availability. With a lot of smaller, easier-to-control systems that can each scale up and down on their own with their respective replicas.
All this upside is traded off with operational complexity, application overhead, and cost of infrastructure to support this new design.
How does it work
Before we can shard a database, we need to answer a few important questions. Your plan will depend on how you answer these questions.
- How do we distribute the data across shards? Are there potential hotspots if data isn't distributed evenly?
- What queries do we run and how do the tables interact?
- How will data grow? How will it need to be redistributed later?
Hotspot 6860189
The term hotspot means that the workload of a node has exceeded the threshold with respect to certain resource (memory, io, and etc.). There is a funny instance of this call the Bieber Bug.Before we get into the next little bit its important to understand the following terminology.
Shard Key is a piece of the primary key that tells how the data should be distributed. With a shard key, you can quickly find and change data by routing operations to the correct database.
The same node houses entries that have the same shard key. A group of data that shares the same shard key is referred to as a logical shard. Multiple logical shards are included in a database node, also known as a physical shard.
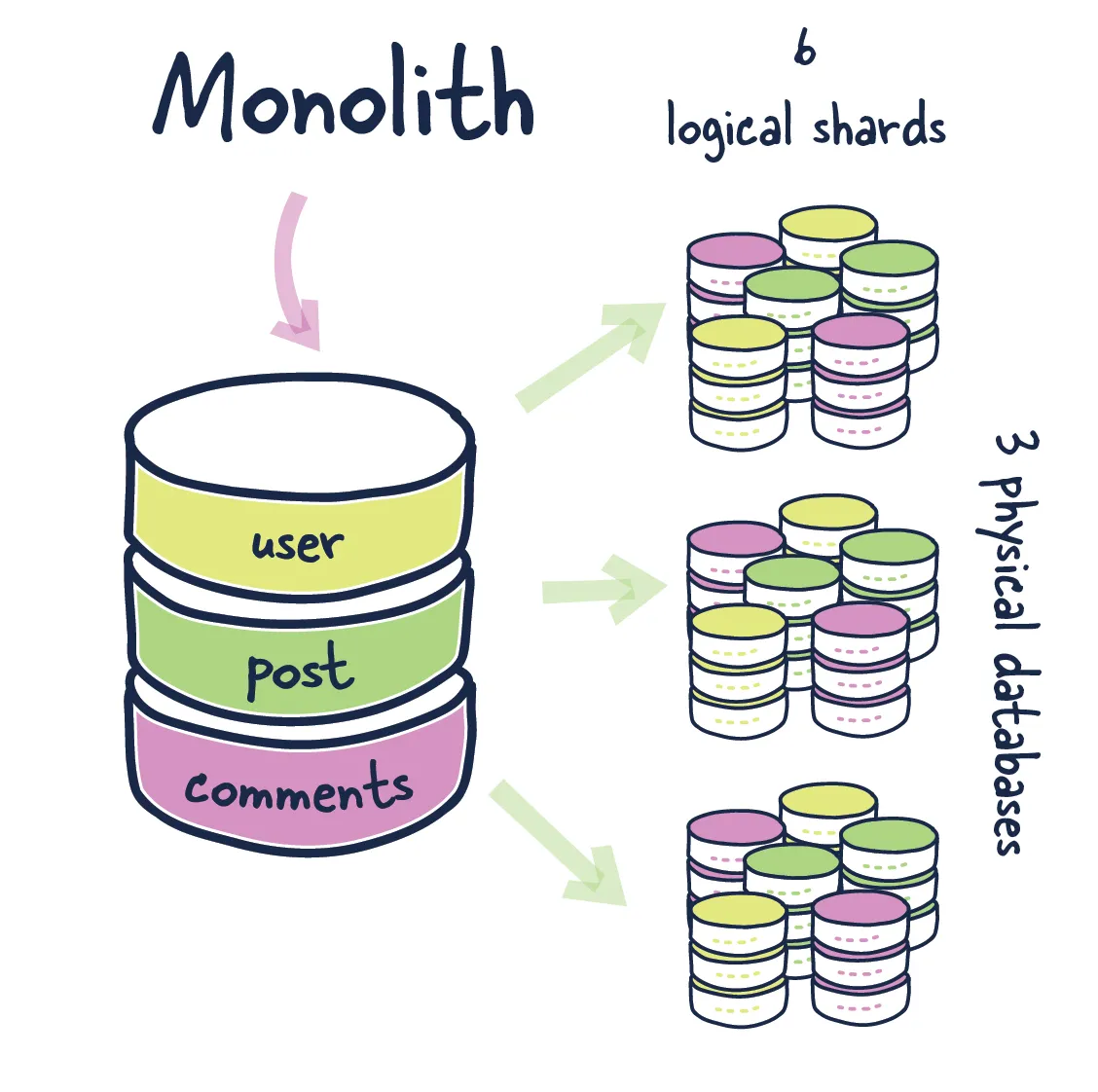 Separating Logical Shards
Separating Logical Shards
The most crucial presumption is also the one that is most difficult to alter in the future. A logical shard can only span one node because it is an atomic unit of storage. The database cluster is effectively out of space in the case where shard is too big for single node.
Key Based Sharding
Algorithmically sharded databases use a hash function to locate data. This allows us given a specific shard key to find the correct physical shard to request the data from.
Data is only distributed by the hash function. It doesn't take the size of the payload or space usage into account. Benefits of hashing allows a more even distribution when a suitable partition key isn't available and location can be calculated on the fly if you have the proper partition key.
 Key based Sharding
Key based Sharding
Downside to such a sharding strategy is that resharding data can be difficult and maintaining consistency while being available is even harder.
Range Based Sharding
Data is divided into chunks depending on the ranges of a certain value in range-based sharding.
 Range based Sharding
Range based Sharding
This requires a look up table to see where the data should be stored. Maintaining the consistency of such a table and obviously picking the ranges here are critical.
When selecting a shard key for this sharding type, it is essential to select one with high cardinality, so the number of possible values for that key is numerous. For example, a key with possible values of North, South, East, and West is of low cardinality since there are only 4. Coupled with that you would ideally prefer a good distribution within that cardinality.
 Even/Uneven Distribution
Even/Uneven Distribution
If everything landed in 50% of the possible values some of your shards would begin to experience hotspots. Running this as an experiment with accurate data is easy enough to do with a few lines of code. First, select a key and ranges and examine the potential distribution.
Relationship Based Sharding
This sharding mechanism keeps related data together on a single physical shard. For example, related data is often spread across several tables in a relational database.
For example, a user and all related data would be sharded to the same physical node for an application like Instagram that would include posts and comments, respectively. You can get more out of a single partition by putting related entities in the same partition. As a result, stronger consistency is maintained throughout the physical shard and fewer cross-physical shard queries.
Cross Shard Transactions
Finally I want to wrap with a few details around complexities that can be introduced when you need to do transactions that span multiple shards. No matter how much you plan, an service or application that is long lived enough will eventually run into a few cross shard transactions.
This essentially means that you need transaction guarantees provided by ACID compliant database, but across shards where the database isn't ensuring such compliance since the data you operating under is outside the scope of the transaction that started it.
This is generally called a global transaction where multiple sub-transactions need to coordinate and succeed. As a general rule the longer a transaction is open the more contention and potentially failure can occur.
Two-phase commit
Two-phase commit is simple in theory but difficult to perform in practise.
- Leader writes a durable transaction record indicating a cross-shard transaction.
- Participants write a permanent record of their willingness to commit and notify the leader.
- The leader commits the transaction by updating the durable transaction record after receiving all responses. (It can abort the transaction if no one responds.)
- Participants can show the new state after the leader announces the commit decision. (They delete the staged state if the leader aborts the transaction.)
Read-and-write amplification in the protocol path is a major issue. Write amplification occurs because you must write a transaction record and durably stage a commit, which requires at least one write per participant. Lock contention and application instability can result from excessive writes. The database must additionally filter every read to ensure that it does not see any state that is dependent on a pending cross-shard transaction, which affects all reads in the system, even non-transactional ones.
Conclusion
We've discussed sharding, when to use it and how it can be set up. Sharding is an excellent solution for applications that need to manage a large amount of data and have it readily available for high amounts of reading and writing. Still, it makes things more complicated to operate. Before you start implementation, you should think about whether the benefits are worth the costs or if there is a more straightforward solution.
















